AI SRE Agent for production incidents and on-call
Using DrDroid, every engineer on your team debugs like your best one.
Trusted by SRE, DevOps, and Infrastructure teams at
How DrDroid can help engineers on call and during production incidents
How an AI SRE could help you with moving from firefighting to building resilience
Today, only your most experienced engineers know which logs to check, which service depends on what, and where to look when something breaks.
Because DrDroid already understands your full infrastructure — services, dependencies, deployments, and ownership — any engineer can ask a question and get an answer with the depth and context of your best SRE.
Watch investigation videos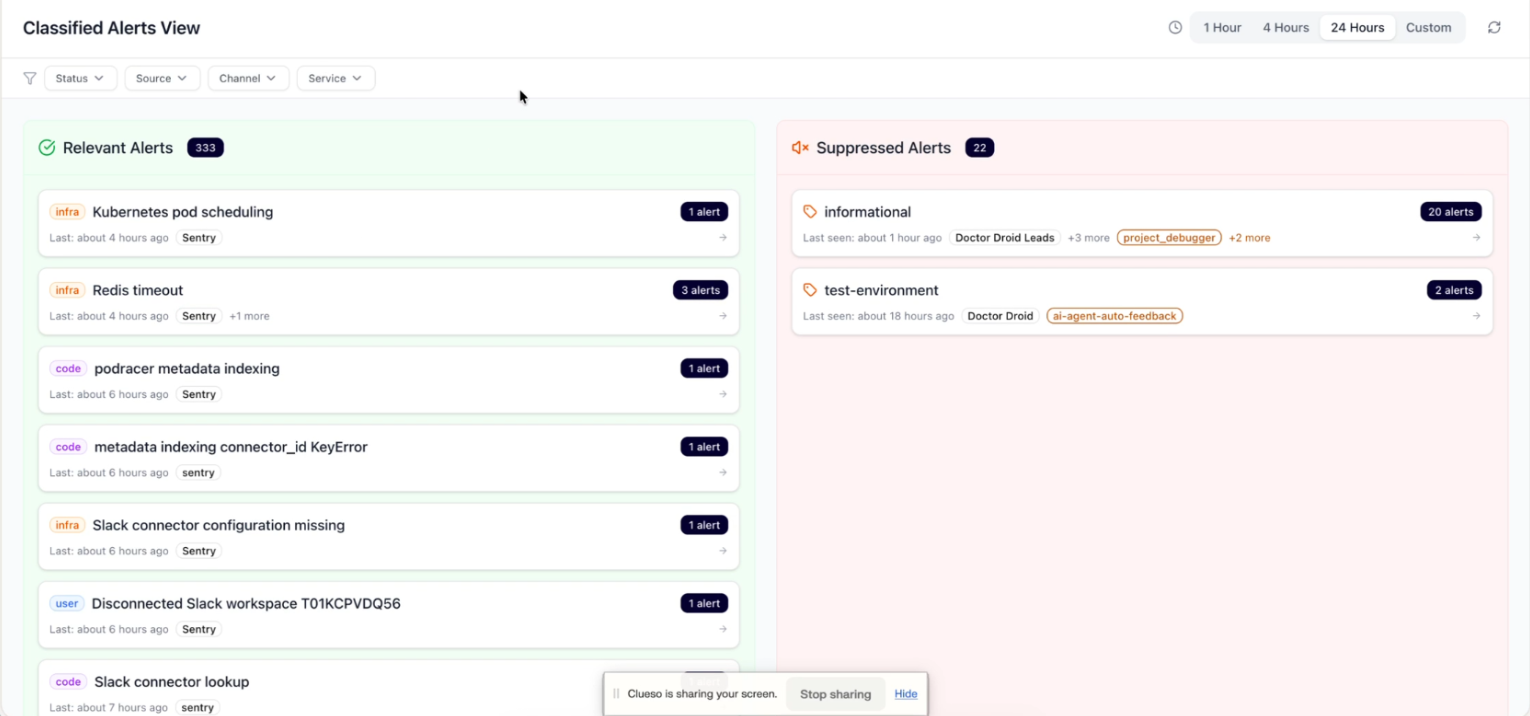
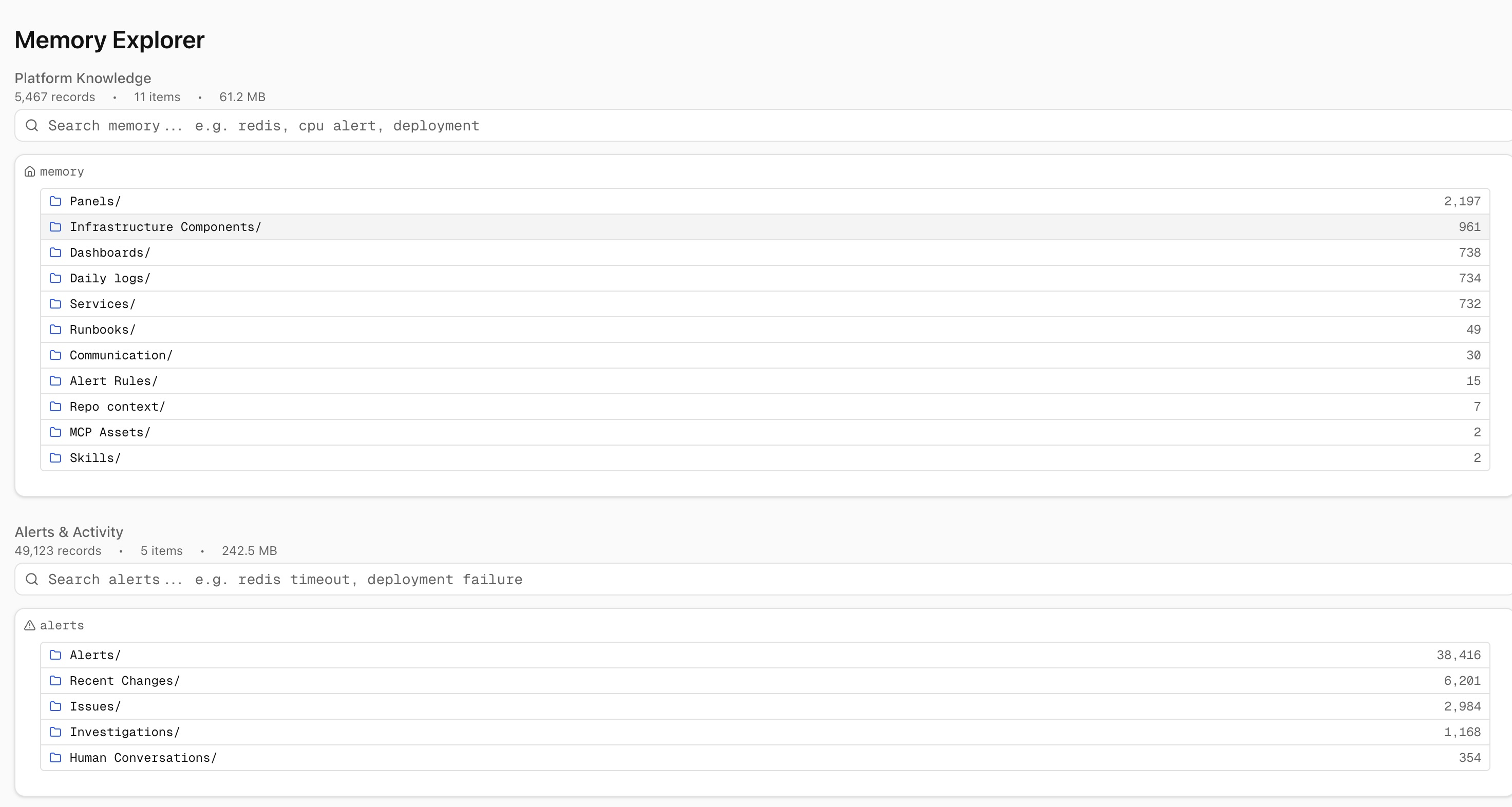
Your infrastructure, fully mapped — before the first investigation
DrDroid maps your tools, code, and infrastructure into a unified context graph — so agents answer questions the way your best engineers would.
Even before the first chat with the agent, DrDroid builds knowledge of what each repo does — what capabilities, APIs, features and workflows it covers, and what languages, frameworks and file structures it uses. Using traces or logs, it also builds connections between multiple repositories.
80+ MCP servers custom built for oncall and production incidents
Connect DrDroid to 80+ predefined MCP servers, from SSH on remote servers to Kubernetes to APM tools or your own MCP servers.










Need something custom?
Add your own integrations — custom MCP servers, custom CLIs, and custom skills — so the agent works with your internal tools too.

What engineering teams say about DrDroid
"Earlier, debugging meant hopping between logs, workflows, and infra dashboards trying to piece together what went wrong. Dr. Droid pulls the context together and points us in the right direction — even someone new to the system can figure things out."

"One time I was woken up at 3am by a pager that escalated. I instantly asked DrDroid to investigate it and in a few minutes, I was able to close the issue directly from Slack."

"DrDroid understood our context too well. It could give recommendations which showed deep understanding of the infrastructure and helped reduce 20-30% cost."

"DrDroid's open-source PlayBooks have been a big help for our SRE and on-call teams. They make it easy to share knowledge, so everyone knows what to do when something goes wrong. This has really helped us fix issues faster and without always needing help from senior engineers."

"We went from 90-day onboarding to 2 weeks. And zero-touch remediation just... works. DrDroid has transformed how we operate our global infrastructure."
Frequently Asked Questions
Everything you need to know about DrDroid
Switch from Firefighting to Proactive Ops
Connect your tools in 15 minutes. See your first automated investigation in under an hour.