Dynamic Memory Retrieval
In this paper, we will explain how using the agentic architectural pattern, called henceforth as "Dynamic Memory Retrieval" (DMR), we were able to build a domain specific agentic platform that delivered consistently higher results compared to any other pattern that we tried.
Table of Contents
In this document, we will be uncovering the following:
Who this document is for:
- • Someone who wants to understand the limits of tasks that AI can do in SRE / production operations / infrastructure tasks
- • Someone who is trying to understand why DrDroid is good at doing production operations (SRE/Infrastructure/DevOps tasks) at large scale operations
- • Any AI engineer who is looking for ways to improve the agent they are already working on
- • Any engineer who is curious about how smarter and stateful agents can be built
- • Any engineer who is interested in understanding what the next layer of AI iteration could look like
Pre-requisites:
To understand the technical implementation explained in the paper, you might need to have an amateur level proficiency in understanding indexing, agentic search and SOTA model capabilities. A beginner level understanding of computational complexity theory will also be helpful, but not necessary.
Introduction:
DrDroid is an AI agent designed for SRE, Infrastructure and Production Operations tasks. The agent is used by engineers on a daily basis in their production operations to do a wide variety of tasks. These could vary from investigating production issues to renewing certificates to infrastructure cost optimisation to deep performance analysis.
DrDroid is NOT a Foundation model provider. DrDroid also does NOT fine-tune models on customers' data. DrDroid is an AIOps platform / AI Agent designed for SRE, infrastructure and production operations.
Basis user feedback who use us for their production operations everyday, our learning has been that DrDroid is able to understand company context deeply, provide high quality root cause analysis and actually behave like a fellow engineer in the team. Users comfortably use internal jargons, watch the agent navigate between multiple tools even when the names aren't exactly matching and often see the agent outpacing their senior engineers in production investigations.
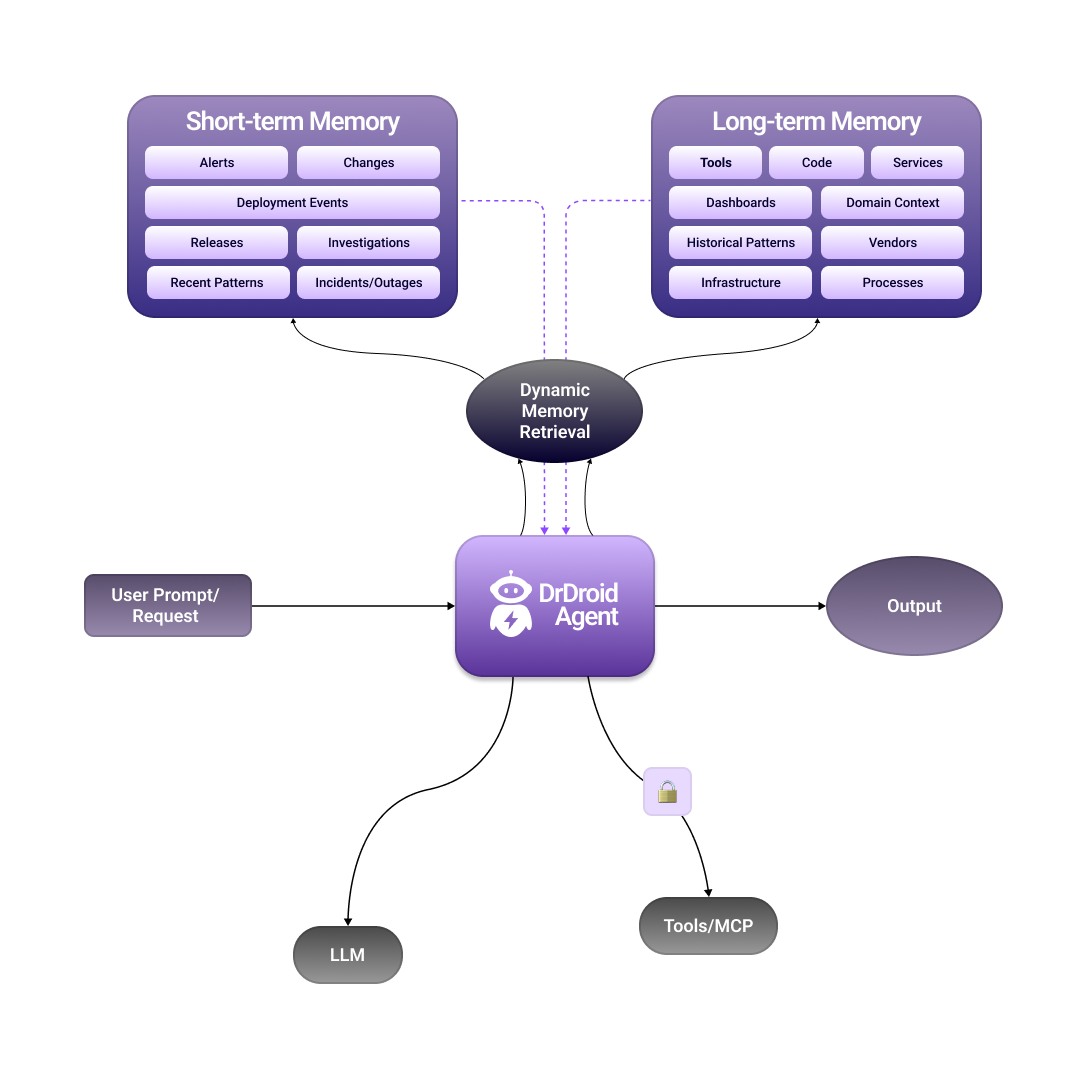
Dynamic Memory Retrieval
The DMR module built by us is one of the core components of why DrDroid is able to understand production issues and queries well. The agent retrieves accurate and most recent information.
1a. System of Record (SoR)
Being an AI Agent that handles production operations is not about just knowing how to code or do problem solving.
Production systems exist and evolve due to business, market and customer requirements. These systems cannot be redesigned overnight and are primarily built through interconnection of 100s of technologies and tools available in the market.
Eventually every engineering team ends up having more than a dozen SoRs. There'll be one for managing deployments, one for traces, etc. etc.
Some of the core entities that matter in production systems: logs, metrics, traces, clusters, alerts, deployments, events, code, databases, infrastructure resources, tickets, incidents . . . the list goes on.
Over time, DrDroid has been custom designed to interact with 80+ SoRs across a wide range of tools used:
| S.No. | Category | Example tools (non-exhaustive) |
|---|---|---|
| 1 | Monitoring Tools | Grafana (LGTM), Prometheus, VictoriaMetrics, VictoriaLogs, Elasticsearch, Opensearch |
| 2 | APM Tools | Datadog, Signoz, NewRelic, Coralogix, ElastAPM |
| 3 | Infrastructure Providers | Azure, AWS, GCP |
| 4 | Core Infrastructure layer | k8s, Terminal |
| 5 | Error Monitoring tools | Sentry, Rollbar, Honeybadger |
| 6 | CI/CD tools | ArgoCD, Jenkins, Github Actions, Gitlab |
| 7 | Code Repositories | Github, Bitbucket, Gitlab |
| 8 | Collaboration Tools | Slack |
| 9 | Ticketing Systems | Jira, Linear |
| 10 | On-Call Tools | PagerDuty, Opsgenie |
| 11 | Databases | MongoDB, Postgres, MySQL, Clickhouse, Elasticsearch, Opensearch |
| 12 | Analytics tools | Posthog, Metabase |
| 13 | Documentation | Notion, Confluence, Wiki |
| 14 | Custom Tools | APIs, MCP Servers |
Data Structures within
Each of these SoRs bring in their own nomenclature and data structure. For instance, everything in Grafana is designed around dashboards (and panels within), data sources and sometimes, alerts. In kubernetes, you have namespaces, deployments, statefulsets, pods and a lot more entities.
DrDroid first extracts Entities of Interest (EoI) from each of these tools which helps create a base layer of records about what the tool's purpose within the company is. Our data extraction here is detailed enough to be able to understand if a client is using Datadog for APM + logs or even just synthetic monitoring. Because of the same reason, if a user refers to a "payment module", the agent will be able to recall that there's a grafana panel about "payments-module" within the "checkout" dashboard.
Once these EoIs are extracted, the next step is to make that data queryable. Here's where we come to the next step: indexing.
1b. The Unified Index
An index is defined uniquely for every client on DrDroid platform — it's a measure of the records.
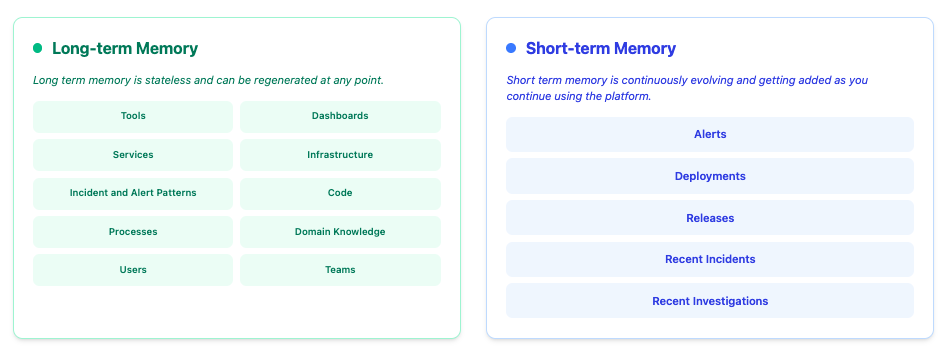
The index size could vary depending on
(a) The expanse & scale of the infrastructure & applications
(b) The integrations added to DrDroid
(c) The duration of time for which your account is using DrDroid & the retention policy (short term memory is continuously evolving based on relevance)
Some sample index sizes:
| Type | Long term records (Stateless, long term retention, can be regenerated) | Short term records (stateful, ephemeral, built over time, limited retention) |
|---|---|---|
| Startup with 1-20 engineers, early stage | 100-2000 records | 10-100 records/day |
| Enterprise with 500+ engineers, multi-tenant, multi-cloud infrastructure | 50k+ records | 2000+ records/day |
What do these indexes look like?
These indexes comprise of different types of records depending on the kind of application or tooling your company uses. Here are a few examples of record types that we have:
1. Service:
A typical example here could be an asset extracted from an APM tool or Kubernetes cluster. This record would have context about the kind of data that the tool has, about that specific entity.
2. Repository readme:
A code repository (e.g. Github) would typically have a record type of "repository readme" — This record is generated by a LLM agent who's proficiency lies in generating a feature + use-case scoping of any given repository.
3. Dashboards:
A tool like Grafana, Datadog or Signoz would often have a dashboard record type. This record would have granular+nested details, from title to variable to panel queries and descriptions.
4. Log Patterns:
Any logging tool would typically have a record type called log pattern. This record would contain the overarching structure of the logs in that tool, the different services/labels that often occur in that log set.
5. Users:
A collaboration or ticketing tool like JIRA or Slack could have a record type Users indexed for it. This would comprise of user information from that tool and often, their unique ID mappings.
6. Table schema:
For a database, table schema/document structure could be a record type, comprising of information of the columns in a table, the kind of data each column stores and (potentially) some sample data.
…
We have 200+ record types across 80+ integrations that we support.
1c. Agentic Retrieval: Extracting the most relevant information
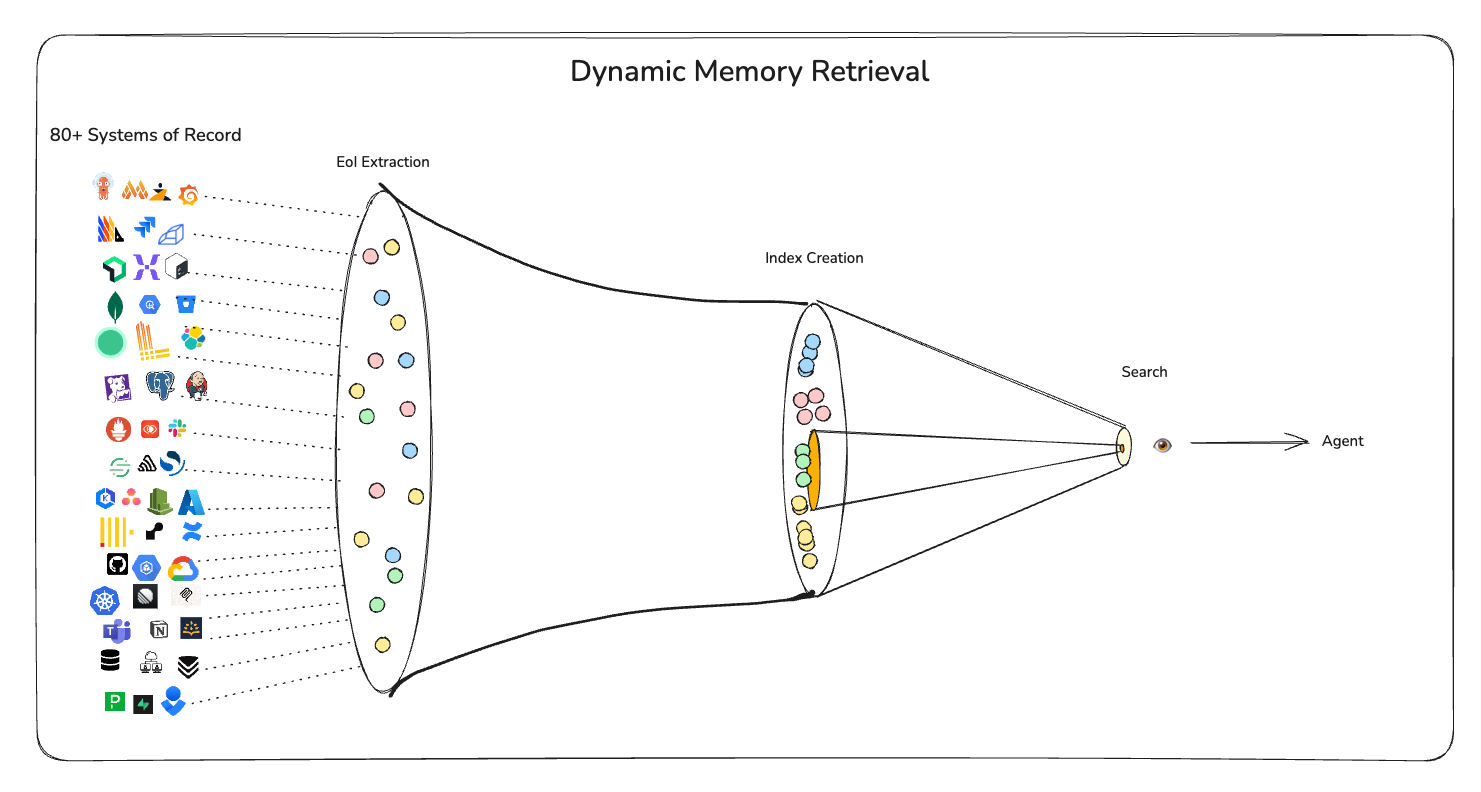
A high quality collection of information that's not searchable easily is like a dictionary where the words are randomly ordered instead of being alphabetically ordered.
While for smaller use-cases just dumping everything works fine (like uploading a group of PDFs to chatGPT or Claude), but at production scale, this could pretty much cross 1M tokens with just a part of the records information. We have seen some records to be as large as 50k tokens, although a typical record would be much much smaller.
To solve relevant search results for the agent, we designed a multi-layered search engine that the agent could reliably use, to explore and extract the EoI. Here were some practices that we followed to drive the max RoI here:
- 1. Agentic Search: We tried doing RAG/embedding based search but soon realised that for engineering search, where keywords/jargons have no semantic meaning and a single character (e.g. us-east-1 vs us-east-2) could mean completely unrelated things, embeddings don't do much of a justice. In fact, keyword based search often made it easier for the agent to initiate discovery as atleast one EoI or scope is often exposed in the question/prompt/alert.
- 2. Hierarchically organised information: Different EoIs have different weightage and priority. A relevant dashboard needs to be of much higher importance than a panel, and so on.
- 3. Multi-attempts: The agent does multiple retrievals as it has more than a handful different ways to filter, sort and query the information, enabling nested discovery of information.
- 4. Segregation of short term & long term records: Short term vs long term memory needs to be treated differently as they have very different objectives/intents, token consumption patterns, refresh rates.
Benefits of using DMR
-
1. High Quality zero-setup investigations:
Users are able to run high quality root cause investigations of production issues on day 0 without requiring any "training data" or "user inputs" or "custom configurations" or "professional services"
-
2. Automated discovery:
- a. Issues and queries related to production systems can have varying degrees of vagueness as well as predictability. When trying to answer such a query, a right starting point becomes a key essential. If a user does not give a very specific tool + starting point combination (which most users very often do not), agent could end up getting lost in a maze full of unrelated information. This wouldn't be hallucination, it would just be non-useful information.
- b. The unified index helps agent get the most likely contexts in which the user or issue is occurring. From our experience, within 2-3 searches (100-200ms) the agent is often getting towards looking in the right direction.
-
3. Smarter hypothesis building:
- a. When debugging, even the right direction could be the dead-end. It's colloquially called hypothesis validation / deduction by elimination (and technically called disjunctive syllogism).
- b. When the agent comes across a dead-end (or sees an hypothesis go flat), it needs to have parallel ideas in mind or else it's going to be a moot investigation.
-
4. Deeper investigations:
- a. While beginning an investigation, one often does not know how many "Why"s are needed to identify what specific change caused the issue. As often discussed mathematically, debugging production issues is an NP-Hard problem (also why a blameless culture in engineering is essential).
- b. Iterating on the go often requires re-searching of context to get to the root cause accurately.
-
5. Reduced agent investigation time/cost:
- a. In simpler situations, the number of attempts it takes for the agent to get to the right data becomes paramount from a commercial aspect.
- b. In production incidents, the difference between 2 minutes and 6 minutes is too big to be ignored.
Scope for improvement in DMR:
- • Pattern identification: Historical pattern of certain EoIs (e.g. alerts) can be beneficial in getting bird's eye view to the agent.
- • Hybrid search with embeddings: Some EoIs like customer support tickets or internal knowledge bases often perform well with a mix of fuzzy and semantic search. Introducing embeddings for certain record types would be beneficial and further improve contextual extraction.
Challenges while building & designing DMR:
-
1. Garbage-in, garbage-out:
To generate high quality DMR, using domain knowledge (in our case, production operations knowledge) and tool behaviours/patterns while defining EoIs and record structures was important. Doing this generically at scale could lead to relevance dilution, and eventually, sub-par DMR performance.
-
2. Continuous updation and maintenance:
- a. While building the records could still happen well, SoRs are continuously evolving their data structures, EoIs and APIs. Keeping the data in sync across 80+ SoRs is essential to ensure high quality results.
- b. Record updations and additions on an ongoing basis require attention to detail to avoid chaotic data structures in the long term.
-
3. Information hierarchy, scoring & search patterns:
Nested record structuring with unequal weightage for record types, parameters and SoRs was essential to avoid noisy search results from DMR.
-
4. Semantic search vs keyword searches:
For parts of the index that might have more semantic relevance than keyword relevance, embeddings need to be appropriately designed for the engine to return good results.
-
5. Maintaining tight coupling between tool/MCP parameters and records:
The intent of the DMR is to drive accelerated + accurate tool calls. Having mismatch in the patterns of records vis-a-vis corresponding tools would lead to dilution of context for the agent and sometimes, confusion (e.g. dashboards as a record but not having a tool called fetch_dashboard_data_with_variables)
Appendix
Challenges in building a production operations agent beyond DMR:
-
1. Context window management:
A single agentic investigation could go for as long as 150 tool calls. While you could restrict the number of tool calls, exploratory investigations often lead to need for larger than usual context windows.
-
2. Log & time series data analytics:
At scale, teams could be managing TBs of hourly log volumes / Billions of timeseries rows. Getting the agent to smartly query and scan through the data efficiently can be challenging and require advanced probabilistic methodologies.
-
3. Remote Integrations:
SoRs used in production could often be isolated from each other and require specialised access to query, especially within a single investigation
-
4. Enabling editing of memory by user
Users often have insightful context that could drive the relevance of DMR even higher. Supporting users with easy and accurate ways of injecting/editing context is crucial, and often, non-negotiable.
-
5. Unknown Unknowns
In production systems, tribal knowledge and isolated information is often tough to escape. Command executions and config changes without easy to spot trails, selective accesses, multiple ways to do the same thing are some of the blockers in getting to an "ideal" state but there are deterministic ways to reduce each of the bottleneck.
-
6. Tool / MCP Design for integrations
While fundamentally, any given API spec can easily be transitioned to an MCP server, not all official MCP servers or APIs are equally good:
- - They could be designed for editing/creating dashboards but your intent might be to query data.
- - They could be designed for raw queries but you might want to query complex data (querying dashboards vs simple promql queries).
- - There could be limitations at API layer itself for a SoR, restricting the types of actions / data fetches that can be done on it.
Interested in learning more about DrDroid?
Discover how our AI-powered SRE agent can transform your production operations with Dynamic Memory Retrieval.